When Code Moves Faster Than Team Memory
Code generation got cheap. Alignment didn't.
In fast-moving teams, the hard part is no longer just writing code. It's keeping track of the decisions, tradeoffs, and investigative context that help everyone stay aligned over time.
That's the problem Watercooler is built to solve.
Watercooler is a structured memory system for durable project context: a shared, versioned place for decision trails, past investigations, corrections, and evolving understanding. It's not a chat log, and it's not a private scratchpad. It's a shared memory layer that helps humans and agents converge on the same understanding of what's happening, what was decided, and why.
And as work speeds up, that problem gets worse, not better. Faster agents, quicker iteration, and more parallel work all increase the cost of drift unless a project has a durable way to preserve and reuse its reasoning.
From the beginning, we didn't want to describe Watercooler through analogy or hype. We wanted to understand its value in a measurable way.
So we asked a different benchmarking question:
What kinds of work improve when project reasoning becomes shared, durable, and retrievable?
That framing matters. Most software benchmarks ask whether an agent can solve a task inside a repo. That's useful, but it doesn't fully test what Watercooler is for.
Watercooler is most valuable when the missing information isn't in the code:
- when a decision was made earlier and only discussed in a thread
- when an investigation happened in a past session
- when an earlier conclusion was later corrected
- when the answer only becomes clear by connecting multiple threads
That led us to benchmark four categories that map directly to the product's value:
- decision recall
- context rehydration
- temporal reasoning
- cross-thread synthesis
We built a 16-task benchmark using real project code and real thread history.
Then we ran the same model in two conditions:
- baseline: access to the codebase only
- with Watercooler tools: access to the same codebase plus Watercooler tools and thread history
The tasks were hand-curated to test decision recall, context rehydration, temporal reasoning, and cross-thread synthesis.
This benchmark does not claim that Watercooler improves every engineering task. It was designed specifically to measure tasks where code alone is not enough and project reasoning matters.
To keep the comparison clean, we kept the task framing the same and changed only the available context.
- The same model was used in both conditions.
- The baseline could access only the repository.
- The Watercooler condition had the same repository plus Watercooler tools and thread history.
- Tasks were pulled from real project context, not generated as artificial memory puzzles.
- The benchmark focused on reasoning-heavy tasks where code is often not the full source of truth.
- Prompts were aligned at the task level; the main variable was access to Watercooler context and tools.
- Evaluation was based on task-specific expected answers or artifacts, not a vague sense of usefulness.
Some representative tasks included recovering a previously agreed production-testing policy, reconstructing an OAuth root-cause investigation, and combining deployment and database threads to answer a cross-thread incident question.
A small example makes the goal clearer. In one task, the agent had to recover an earlier production-testing policy that had been discussed and settled outside the codebase. The baseline could inspect the repo, but it had no access to the conversation where the policy was decided. The Watercooler-enabled version could recover that decision from thread history. That's exactly the gap this benchmark is designed to measure.
The clearest result came from that 16-task run.
Overall performance
- Without Watercooler tools: 4/16 (25%)
- With Watercooler tools: 15/16 (93%)
That's a 68 percentage point improvement.
Category-level breakdown
- Decision recall: 40% → 100%
- Context rehydration: 0% → 100%
- Temporal reasoning: 67% → 67%
- Cross-thread synthesis: 0% → 100%
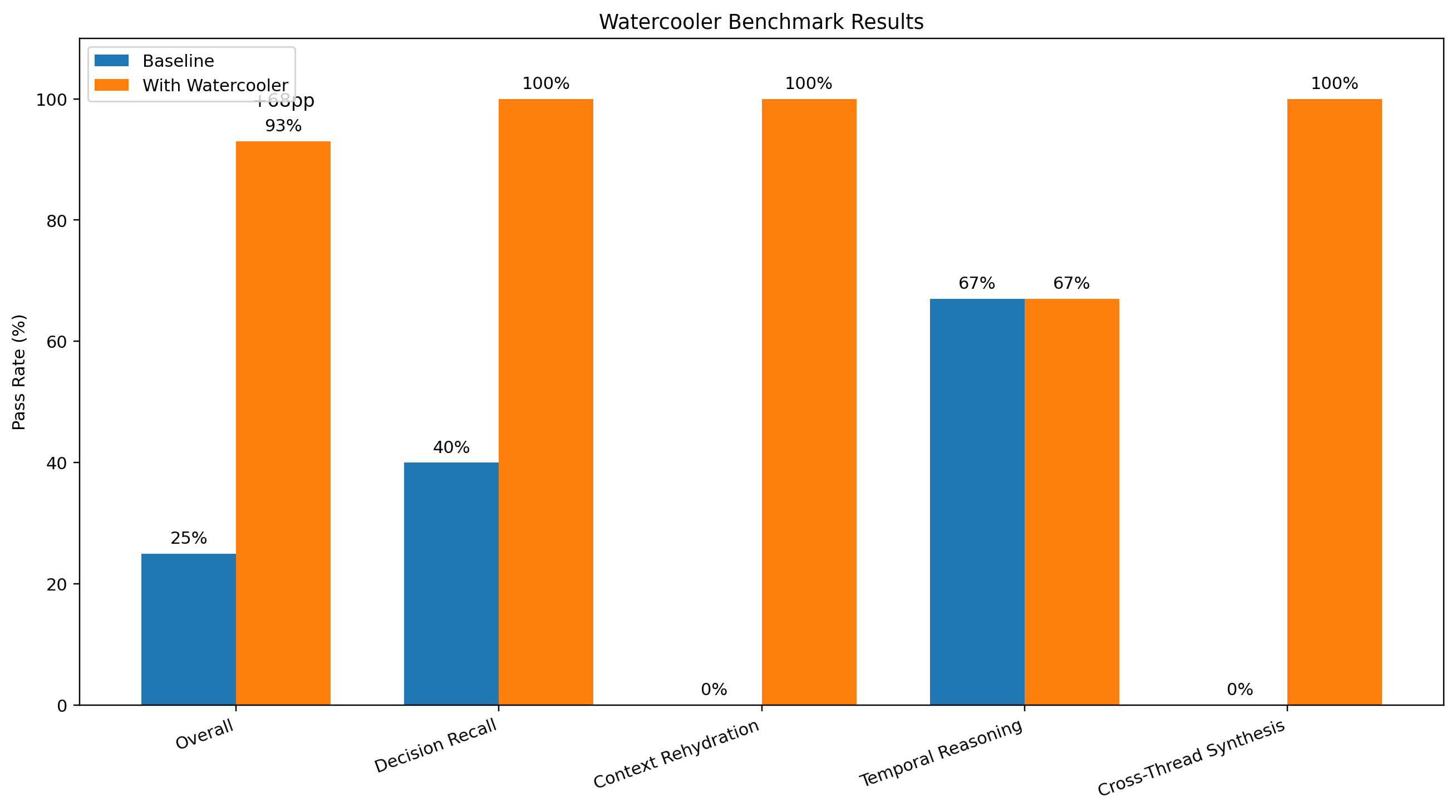
What matters most isn't just the headline number. It's the pattern.
Watercooler helped the most in exactly the places where code alone is least sufficient:
- recovering prior decisions
- reconstructing earlier work
- synthesizing information across threads
Temporal reasoning stayed flat overall, and that's useful too. Some "what's current?" questions are already answerable from the present codebase. Watercooler doesn't replace reading code. It adds the durable context and decision history that code alone doesn't preserve.
That's the distinction we wanted the benchmark to make visible.
So what does this say about the product?
It's evidence for an important slice of the thesis: durable shared project memory improves performance on tasks where project reasoning matters.
It's not the entire claim. But it is a measurable proof point for one core kind of value.
Watercooler isn't just "memory for agents." It's infrastructure for convergence.
It creates a shared memory surface where reasoning can accumulate, be revised, be cited, and be reused across the life of a project. Code remains one layer. Communication remains another. Watercooler adds the durable context between them.
That's why it becomes most valuable where teams are most likely to lose alignment: across sessions, across people, across branches, and across time.
And that matters even more now.
As coding agents become more capable, the bottleneck shifts.
The challenge is no longer just generation. It's coordination and convergence:
- How do teams avoid silently diverging assumptions?
- How does a cold-start session inherit real project context?
- How do humans and agents reuse reasoning instead of repeating it?
We don't think the answer is only better models or faster runtimes.
Part of the answer is durable, shared project memory.
Git remembers what changed.
Watercooler preserves why the team changed it.