The Tool I Built for Agents Explained My Own Code to Me
AI makes it cheaper to produce the next artifact. It does not make it cheaper to know whether that artifact still follows the path the team intended to be on.
Most engineering work is not Markovian. The right next step is rarely visible from the current state alone, because the next move depends on trajectory: original intent, rejected approaches, temporary compromises, stale assumptions, forgotten constraints, and decisions that are now only partially visible in the repository itself.
Software has repo state. Teams have reasoning state. Git is very good at preserving the first one. The second is much easier to lose.
That distinction became unexpectedly personal when I ran an onboarding tool I built for agents against one of my own long-running repositories. I expected it to help agents understand unfamiliar code. Instead, it helped explain my own project back to me, not because it discovered some hidden truth, but because it forced the project to become inspectable again.
The repo was mine, but not really familiar
The repository was not new to me. It was a long-running NLP and document-analysis project tied to mining and exploration workflows, including geological report parsing, PDF segmentation, drillhole classification, entity extraction, and corpus normalization.
Projects like this rarely evolve as clean product architectures. They grow through repeated contact with messy reality: new document formats, parser exceptions, quick scripts that survive because they handle edge cases nothing else handles, and migrations that pause because downstream tooling still depends on the older layout.
The repo had accumulated years of those interactions: useful experiments, partial migrations, evolving assumptions, and utility paths that quietly became load-bearing. The system still reflected that history, but mostly as residue. The project had code, tests, commits, scripts, docs, and history. What it no longer had in one coherent place was the current explanation of why the system had this shape.
Git preserved the evolution of repo state. The implementation still existed. The rationale was harder to recover.
Repo state is visible. Reasoning state drifts.
The onboarding pass surfaced ordinary things. Older scaffolding was still in the tree, a packaging migration had started but not finished, the README described an earlier layout, a few files disagreed about supported Python versions, and some imports reflected newer structure while older tests still assumed previous paths.
None of this was mysterious. Applied ML and data systems often preserve awkward paths because delivery, downstream jobs, and hard-won data understanding all matter.
The system keeps producing value, so the work keeps moving. Over time, though, the current state stops carrying enough of the reasoning that originally made the state make sense.
We usually describe this as tech debt, stale documentation, cleanup, or refactor work. Those categories are real, but they do not always name the deeper loss. Often the problem is the gradual separation of implementation from rationale. The code remains, while the reasoning disperses.
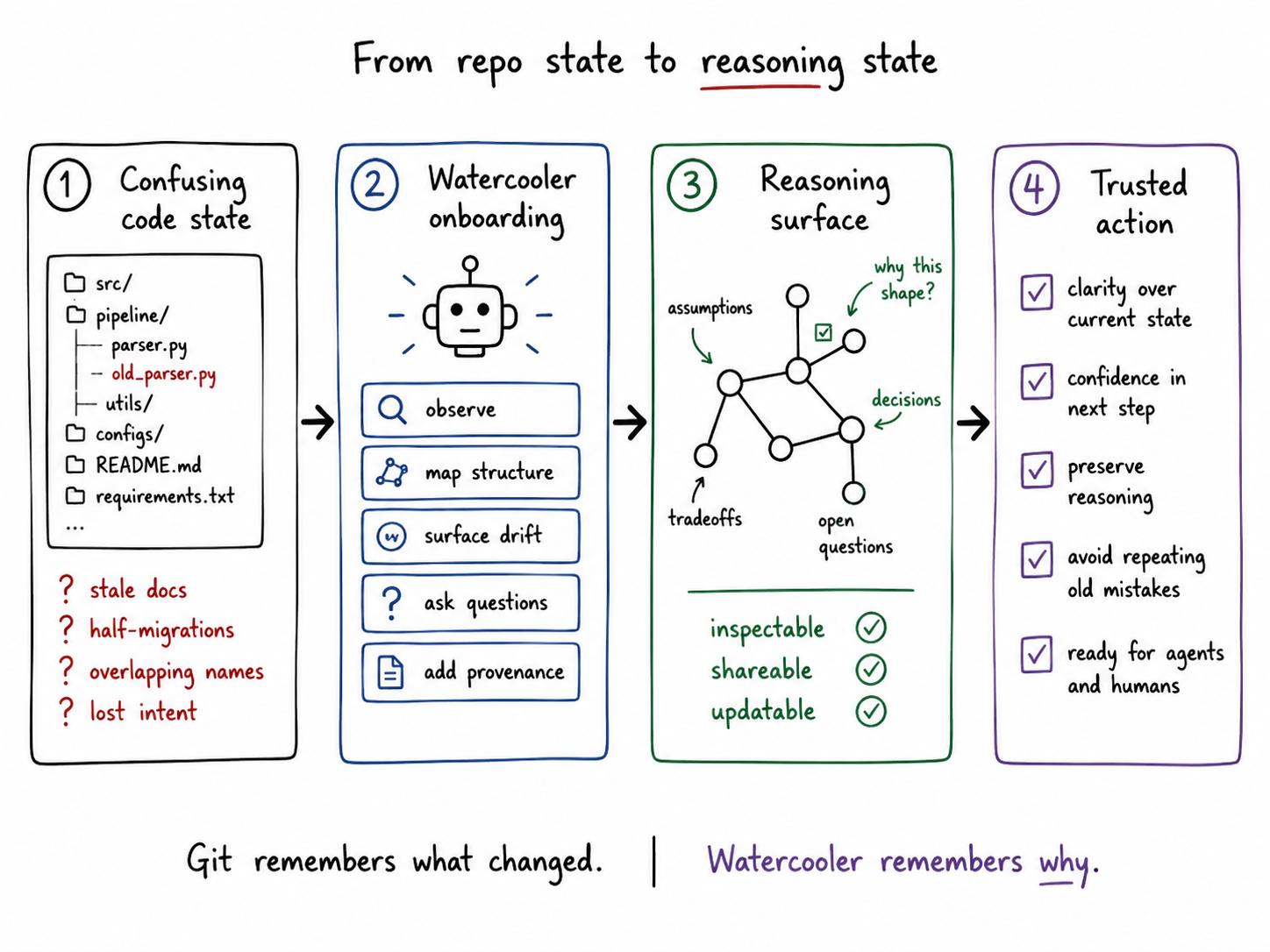
What the onboarding pass actually did
Watercooler onboarding did not try to generate a prettier README. It walked the repository and created structured seed threads around architecture, product intent, system layout, risk surfaces, documentation contracts, test surfaces, entry paths, recent activity, and migration boundaries.
The point was not to make the repo sound organized. The point was to make its current state reviewable.
Each thread separated observed facts, inferred structure, drift findings, unresolved questions, and provenance. Every claim had to point back to inspectable evidence. Without provenance, onboarding summaries easily become confident essays about systems. With provenance, the system has to keep asking harder questions: what is observable, what is inferred, what appears stale, which claim comes from which file, and which contradiction is real.
That discipline surfaced the project's shape quickly. It separated newer segmentation work from older batch-worker code, identified the half-finished layout migration, exposed README drift, and made import mismatches and Python-version inconsistencies visible as systemic issues rather than isolated annoyances.
Individually, none of those findings surprised me. Together, they changed the surface I was looking at. Before onboarding, the repo existed as a familiar mixture of files, intentions, postponed cleanup, and memory. After onboarding, it became a set of inspectable claims.
By reasoning surface, I mean a reviewable set of claims, evidence, unresolved questions, and decision candidates. The value was not that the tool produced a better story about the repo. The value was that it made the story easier to challenge.
Structured reading is different from summarization
A summary tries to compress a repo into an answer. A structured read keeps the repo open as a set of claims, evidence, questions, and unresolved reasoning.
Watercooler did not magically recover original intent. It did not decide what the architecture should become. It did not rewrite the system. It created a reasoning surface that could hold important distinctions: what was observed, what was inferred, what had drifted, what remained unresolved, and where human judgment was still required.
That distinction matters. The goal is not to replace human understanding with an agent's fluent explanation. The goal is to make reasoning durable enough that humans and agents can inspect it together.
The onboarding pass forced the repository to answer the same questions any new contributor would ask: what the system is for, what is active versus legacy, where the current architecture actually lives, where docs disagree with implementation, which assumptions are transitional, and what the next person should inspect first.
Those questions are easy to stop asking once a project becomes familiar. Familiarity becomes its own blind spot. You stop reading the repository directly and begin remembering it instead. Long-running projects eventually become unfamiliar even to the people who built them, not because they forgot the code, but because they carry too much stale context.
The onboarding pass treated the project as unfamiliar. That was exactly what I needed.
Onboarding is the bootstrap path
This onboarding pass is not the normal Watercooler workflow. It is the bootstrap path.
The system was reading an already-evolved repository and reconstructing enough structure to make the current state legible again. That is useful, but it is still catch-up work. The fuller intent is to capture reasoning while the work is happening, so future contributors do not have to reconstruct it from code, stale docs, and memory.
In the normal Watercooler loop, humans and agents record plans, critique, decisions, handoffs, corrections, and closures as part of the work itself. That reasoning is not merely stored. It is exposed to role-separated planning, critique, testing, handoff, and closure before it hardens into project memory.
Agents can surface structure, contradictions, likely drift, and evidence, but they should not silently promote those findings into settled project truth. Humans remain responsible for moments that require authority and judgment.
The onboarding story is therefore only one part of the model. It is the recovery mode. The real goal is to avoid needing as much recovery later.
Approval gates need trajectory
This is where the story stops being personal.
Many organizations are improving AI tooling faster than they are improving the organizational structures around the tooling. Artifact production is accelerating, but reasoning visibility is not. The review gates are still there: approval, oversight, architecture review, compliance, migration signoff, and deployment authority. Yet if reviewers only see the current artifact, they are making judgments from snapshots.
Real engineering judgment requires trajectory: why this path was chosen, what was rejected, which compromise was temporary, which stale assumption is still steering the work, which old constraint still matters, and which one expired months ago.
Those questions do not reliably exist in the current repo state alone.
Remote work makes this harder because ambient context transfer disappears first. The old water cooler effect was not just social noise; it was continuous informal correction. Someone overheard the plan, someone remembered the constraint, someone interrupted an incorrect assumption before it hardened into implementation.
Remote organizations have to rebuild that structure deliberately. AI-assisted organizations need to rebuild it even more deliberately, because plausible next steps can now be generated faster than organizations can remember why previous steps happened.
Documentation entropy is a systems problem
Documentation entropy is not laziness. It emerges because teams are constantly balancing delivery against explanation. A parser must handle another document format, a migration has to pause, a customer needs the result now, and a README sentence that was true last month quietly becomes false. Nobody failed morally. The system kept moving.
The problem is that reasoning is rarely preserved with the same discipline as implementation. Teams need durable access to why the system has this shape, which parts are intentional, which are transitional, which are stale, and where human judgment should still intervene.
Some findings should become active decision traces. Some should remain questions. Some should be preserved as superseded context. The point is not to turn the repository into a single explanation, but to preserve the project's changing belief structure.
The mirror
The tool I built did not fix my project. It did not finish the migration, clean the imports, reconcile the Python-version contracts, or rewrite the README. What it did was smaller and more useful: it made the current state inspectable alongside the reasoning questions the state itself raised.
That changed the shape of the next step. The problem was no longer simply to figure out what was going on. The problem became more precise: which drift matters, which migration should finish first, what deserves preservation, what deserves deletion, which assumptions should become explicit, which decisions deserve durable traces, and what should remain untouched because it still reflects a real operational constraint.
That is where AI-assisted work becomes more trustworthy. Not when the system sounds intelligent, but when the work becomes easier to inspect.
I originally built Watercooler onboarding so agents could enter unfamiliar repositories more effectively. It did help with that. But the more interesting result was that it helped me re-enter a familiar repository with less stale memory.
The onboarding pass became a mirror. It exposed the difference between the project as I remembered it, the project as the repository currently expressed it, and the project a future contributor would actually have to understand.
That difference is where much of modern engineering work now lives. Not in the code alone, but in the evolving reasoning around the code. Watercooler gives teams a durable reasoning surface for codebases that outlive any one session, agent, or contributor's memory. If that reasoning is not preserved, every future session pays the reconstruction cost again.